Studenten
Webdesign
WordPress Website
Leichte Selbstverwaltung
Mobile-Friendly
Für Handys angepasst
SEO
Für Google optimiert
Website erstellen lassen
Professionelles Webdesign
Website erstellen lassen in Deutschland, Österreich und Schweiz
Willkommen bei Studenten Webdesign! Sollten Sie eine professionelle Erstellung Ihrer eigenen Website oder Homepage in Deutschland, Österreich oder der Schweiz anstreben, so sind Sie bei uns genau an der richtigen Stelle. Wir präsentieren Ihnen speziell angefertigte Webdesign-Lösungen, die optimal auf die Bedürfnisse von Selbstständigen, Freiberuflern und kleinen bis mittleren Unternehmen abgestimmt sind. Ob Sie eine individuelle Webseite oder eine umfangreiche Firmenwebsite benötigen, wir setzen uns mit Leidenschaft und Hingabe für Ihre Projekte ein. Im Weiteren präsentieren wir Ihnen einige unserer bisherigen Arbeiten als Referenzen.
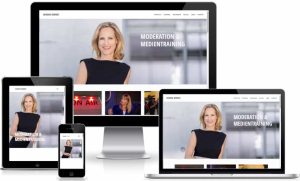
Moderatorin

Tourismus
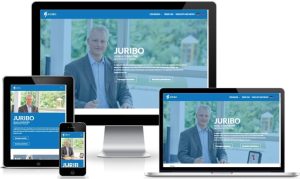
Rechtsanwalt
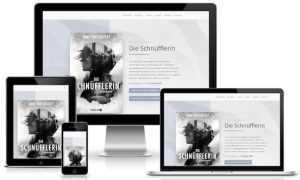
Autorin

Touranbieter

Coaching
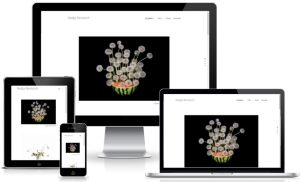
Fotograf
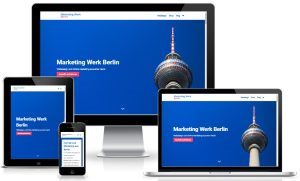
Marketing Agentur
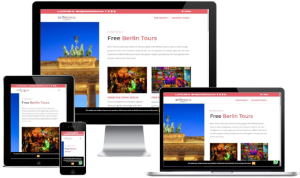
Walking Tours
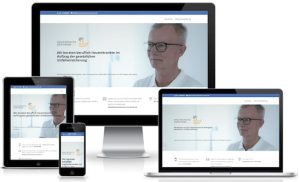
Hautklinik
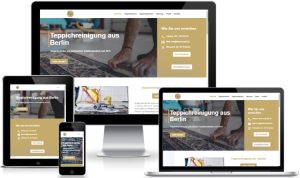
Teppichreinigung
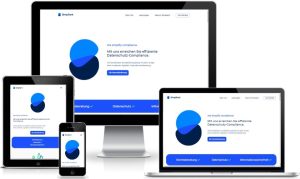
Datenschutz
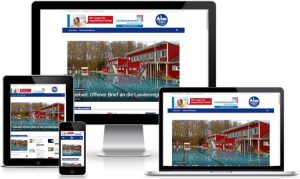
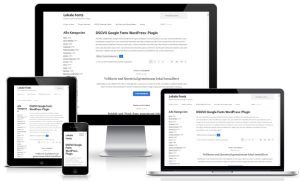
WordPress Plugins

Blockchain

Musiker
Webdesign
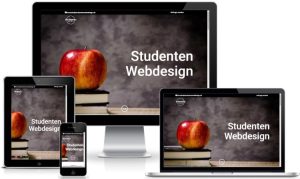
Webdesign
- Kostenfreie Erstberatung
- Entwickelt mit WordPress
- Suchmaschinen-Optimierung
- Homepages
- Firmenwebsites
Welche Webdesign-Dienstleistungen bieten wir an?
Unser Angebot umfasst eine Vielzahl von Webdesign-Diensten, darunter die Erstellung von neuen Websites, die Modernisierung bestehender Websites und die Suchmaschinenoptimierung (SEO). Wir helfen Ihnen gerne dabei, Ihre Homepage erstellen zu lassen, um Ihre Online-Präsenz zu stärken und Ihr Unternehmen erfolgreich zu repräsentieren. Unsere Websites sind responsiv gestaltet und somit für die Anzeige auf verschiedenen Geräten optimiert, zudem bieten wir auch Lösungen für E-Commerce-Websites an.
Welche Vorteile bietet die Zusammenarbeit mit uns?
Wir verfügen über langjährige Erfahrung im Webdesign und liefern hochwertige Ergebnisse. Wir sind stets bemüht, unseren Kunden den besten Service zu bieten und bieten flexible Preisoptionen sowie transparente Kommunikation während des gesamten Projektprozesses. Wenn Sie sich für uns entscheiden, können Sie sicher sein, dass wir Ihnen eine professionelle Website erstellen, die Ihren Anforderungen entspricht.
Wie starten wir ein Projekt zusammen?
Um Ihre Website erstellen zu lassen, nehmen Sie einfach Kontakt mit uns auf und teilen Sie uns Ihre Anforderungen und Wünsche mit. Wir werden dann ein Angebot erstellen und mit Ihnen zusammenarbeiten, um das Projekt von Anfang bis Ende zu planen und umzusetzen.
Wie lange dauert es, eine Website zu erstellen?
Die Dauer eines Website-Projekts hängt von verschiedenen Faktoren ab, wie der Größe und Komplexität der Website, den Anforderungen des Kunden und der Verfügbarkeit von Ressourcen. In der Regel dauert es einige Wochen, um eine Website zu erstellen. Wir werden aber immer transparent kommunizieren und den Fortschritt des Projekts mit Ihnen besprechen.
Kann ich die Website später selbst bearbeiten?
Ja, das ist kein Problem. Alle unsere Websites sind so erstellt, dass Sie im Nachhinein Text oder Bildänderungen selbst vornehmen können. Sollten Sie diese jedoch lieber durch uns machen lassen wollen, bieten wir auch gerne Support an.
Wie sieht es aus mit der Sicherheit der Website?
Wir setzen auf beste Sicherheitsmaßnahmen bei der Erstellung unserer Websites. Zweistufige Authentifizierung und wöchentliche externe Backups sorgen für die nötige Sicherheit, um es Hackern schwer zu machen und auch bei Systemausfällen vorzubeugen.
Kann ich Updates selbst vornehmen?
In den meisten Fällen können Sie Ihre Website selbst oder automatisch aktualisieren lassen. In Ausnahmesituationen, wie bei besonders großen Nachrichtenportalen oder anspruchsvolleren Onlineshops, empfehlen wir jedoch Vorsicht bei den Updates. Bei den meisten Websites ist die Aktualisierung jedoch kein Problem und kann automatisch von WordPress selbst gemacht werden.
Wie hoch sind die Kosten?
Wir bieten günstige Tarife für die Erstellung von Websites, solange die Umsetzung wenig Ressourcen verbraucht. Eine anspruchsvolle Website benötigt jedoch viel Arbeit, weshalb sich ein hoher Bedarf nach Qualität im Preis ausdrückt.
Webdesign
- Kostenfreie Erstberatung
- Entwickelt mit WordPress
- Suchmaschinen-Optimierung
- Homepages
- Firmenwebsites
Logodesign
Logodesign
- Logodesign
- Visitenkarten und Flyer
- Briefköpfe
- E-Mail-Signaturen
- Branding Guidelines
- Corporate Identity
Welche Logodesign-Dienstleistungen bieten wir an?
Wir bieten Dienstleistungen im Bereich Logo-Design an, einschließlich der Erstellung von Geschäftsausstattungen und der Entwicklung von Markenidentitäten. Wir helfen Ihnen dabei, ein repräsentatives und professionelles Logo zu erstellen, das Ihrem Unternehmen entspricht.
Was ist das Ziel unserer Logodesign-Dienstleistung?
Unser Ziel ist es, professionelle und einzigartige Logos zu gestalten, die das Markenimage unserer Kunden widerspiegeln und ihre Online-Präsenz stärken. Wir arbeiten eng mit unseren Kunden zusammen, um individuelle Lösungen für ihre spezifischen Bedürfnisse zu entwickeln. Die Logoerstellung beinhaltet ebenfalls Visitenkarten, E-Mail-Signaturen, Briefköpfe, Flyer und Branding Guidelines. Alles, was Sie zu einem erfolgreichen Internet-Auftritt benötigen, bekommen Sie von uns.
Wie läuft der Projektprozess ab?
Um ein Logo-Design-Projekt zu starten, nehmen Sie einfach Kontakt mit uns auf und teilen Sie uns Ihre Anforderungen und Wünsche mit. Wir werden dann ein Angebot erstellen und mit Ihnen zusammenarbeiten, um das Projekt von Anfang bis Ende zu planen und umzusetzen. Während des Projekts werden wir transparent kommunizieren und den Fortschritt des Projekts mit Ihnen besprechen.
Zuerst versuchen wir die Kernbotschaft Ihrer Marke zu definieren. Was zeichnet Ihren Betrieb genau aus, was ist die zentrale Botschaft und wen wollen Sie ansprechen? Basierend darauf versuchen wir ein Logo zu entwickeln, das Hinweise zu Ihrer Botschaft enthält, sodass Sie sich von anderen Anbietern unterscheiden.
Wie ist es mit Flyern und Visitenkarten?
Anhand des Logos entwickeln wir dann Ihre Visitenkarten, Flyer, Briefköpfe und alle weiteren Materialien, die zu einem ordentlichen Branding gehören. Sie werden nicht einfach nur eine Homepage haben, Sie werden ebenfalls eine unverwechselbare Marke bekommen, die sich nicht kopieren lässt.
Wie hoch sind die Kosten?
Wir bieten Logo-Design nur zusammen mit der Erstellung einer Website an. Die Kosten des Logo-Designs hängen von der Komplexität des Logos ab, wenn Sie zum Beispiel ein Maskottchen-Logo designen lassen möchten, sind die Kosten höher als bei einem monochromen Schriftzug im Linienstil.
Jede Art von Logo hat unterschiedliche Kosten, da sich der Aufwand stark unterscheidet. Schreiben Sie uns an und wir können Ihnen eine Reihe von Referenzen zeigen, die unterschiedliche Stile von Logos beinhalten. Gemeinsam, können wir den Logo-Stil finden, der zu Ihrer Marke am besten passt.
Kostenfreies Erstgespräch
Über den untenstehenden Button gelangen Sie zu unserem Kontaktformular, wo Sie uns direkt schreiben können. Wir freuen uns auf Ihre Anfrage und werden uns schnellstmöglich bei Ihnen melden!